Existing Transformer models for monocular 3D human shape and pose estimation often face computational and memory limitations due to their quadratic complexity with respect to feature length. This constraint hinders the effective utilization of fine-grained information present in high-resolution features, which is crucial for accurate 3D reconstruction.
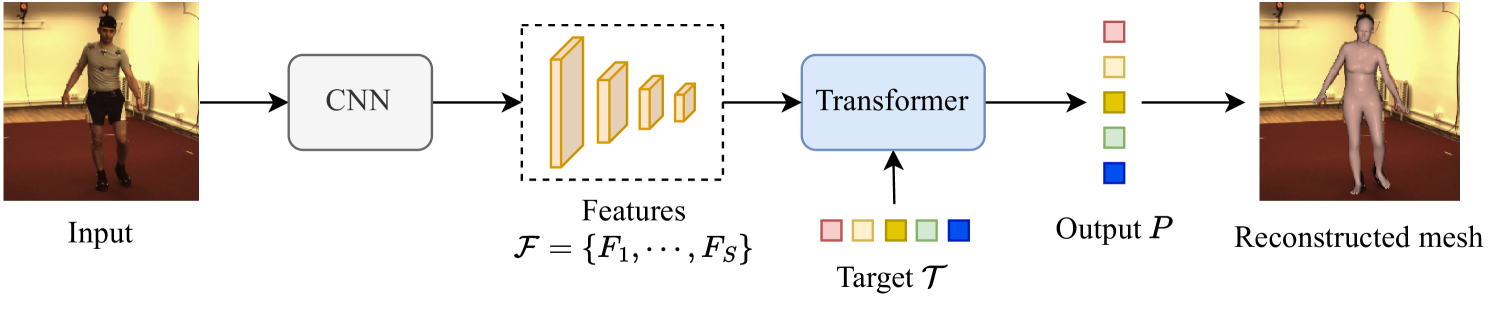
To address this challenge, the researchers propose SMPLer, an innovative SMPL-based Transformer framework. SMPLer incorporates two key components: a decoupled attention operation and an SMPL-based target representation. These elements enable the efficient exploitation of high-resolution features within the Transformer architecture, leading to improved reconstruction accuracy.
Building upon these core designs, the authors introduce several novel modules, including a multi-scale attention mechanism and a joint-aware attention module. These additions further enhance the reconstruction performance by capturing intricate details and leveraging joint-specific information.
Extensive experiments demonstrate the effectiveness of SMPLer against existing state-of-the-art methods for 3D human shape and pose estimation, both quantitatively and qualitatively. Notably, the proposed algorithm achieves an impressive Mean Per-Joint Position Error (MPJPE) of 45.2 mm on the challenging Human3.6M dataset, outperforming the Mesh Graphormer by more than 10% while requiring fewer than one-third of the parameters.
SMPLer represents a significant advancement in the field of monocular 3D human shape and pose estimation, offering an efficient and accurate solution that leverages the power of Transformers while overcoming the limitations of existing approaches. By effectively utilizing high-resolution features and incorporating novel attention mechanisms, SMPLer paves the way for more precise and computationally efficient 3D human reconstruction from monocular images.
