Proximal Policy Optimization (PPO), a popular on-policy reinforcement learning (RL) method, is not immune to the challenges posed by non-stationarity in RL environments. Despite the common belief that on-policy methods can train indefinitely, this study reveals that PPO agents are also susceptible to feature rank deterioration and loss of plasticity, which can lead to a collapse in performance.
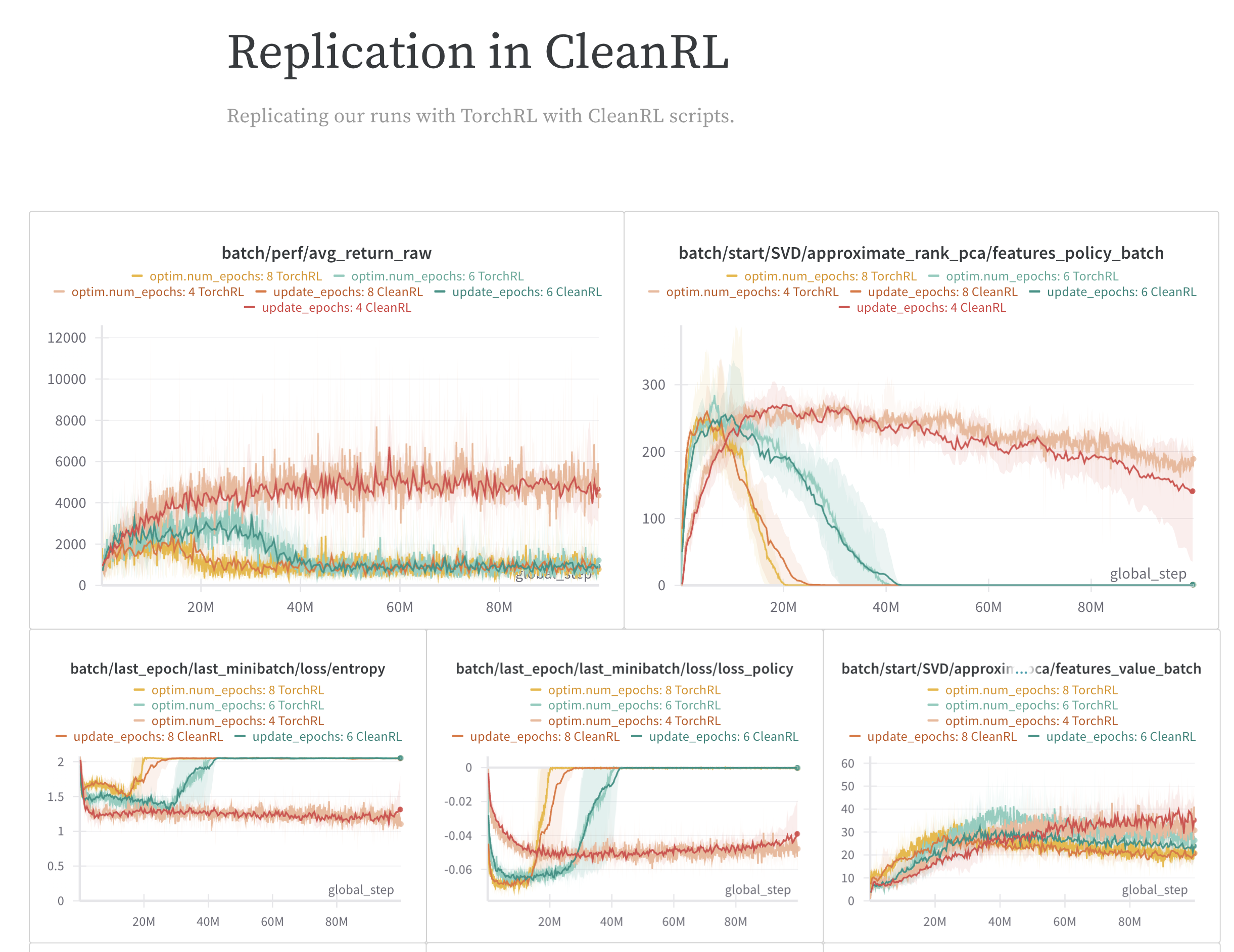
The authors empirically investigate the representation dynamics in PPO agents across the Atari and MuJoCo environments. Their findings show that stronger non-stationarity exacerbates the issue of representation collapse, ultimately causing the actor’s performance to deteriorate, regardless of the critic’s performance. This observation highlights the importance of addressing representation dynamics in on-policy RL methods.
The study draws connections between representation collapse, performance collapse, and trust region issues in PPO. To mitigate these problems, the authors introduce Proximal Feature Optimization (PFO), a novel auxiliary loss function. When combined with other interventions, PFO demonstrates that regularizing the representation dynamics can significantly improve the performance of PPO agents.
This research sheds light on a previously overlooked aspect of on-policy RL methods and emphasizes the need for techniques that can maintain stable and informative representations in the face of non-stationarity. The proposed PFO auxiliary loss function offers a promising solution to this challenge, paving the way for more robust and efficient on-policy RL algorithms.
