Multimodal Large Language Models (MLLMs), also known as Large Vision-Language Models (LVLMs), have shown significant advancements and remarkable capabilities in multimodal tasks. Despite these promising developments, MLLMs often produce outputs that are inconsistent with the visual content. This inconsistency, known as hallucination, poses considerable challenges to their practical deployment and raises concerns about their reliability in real-world applications.
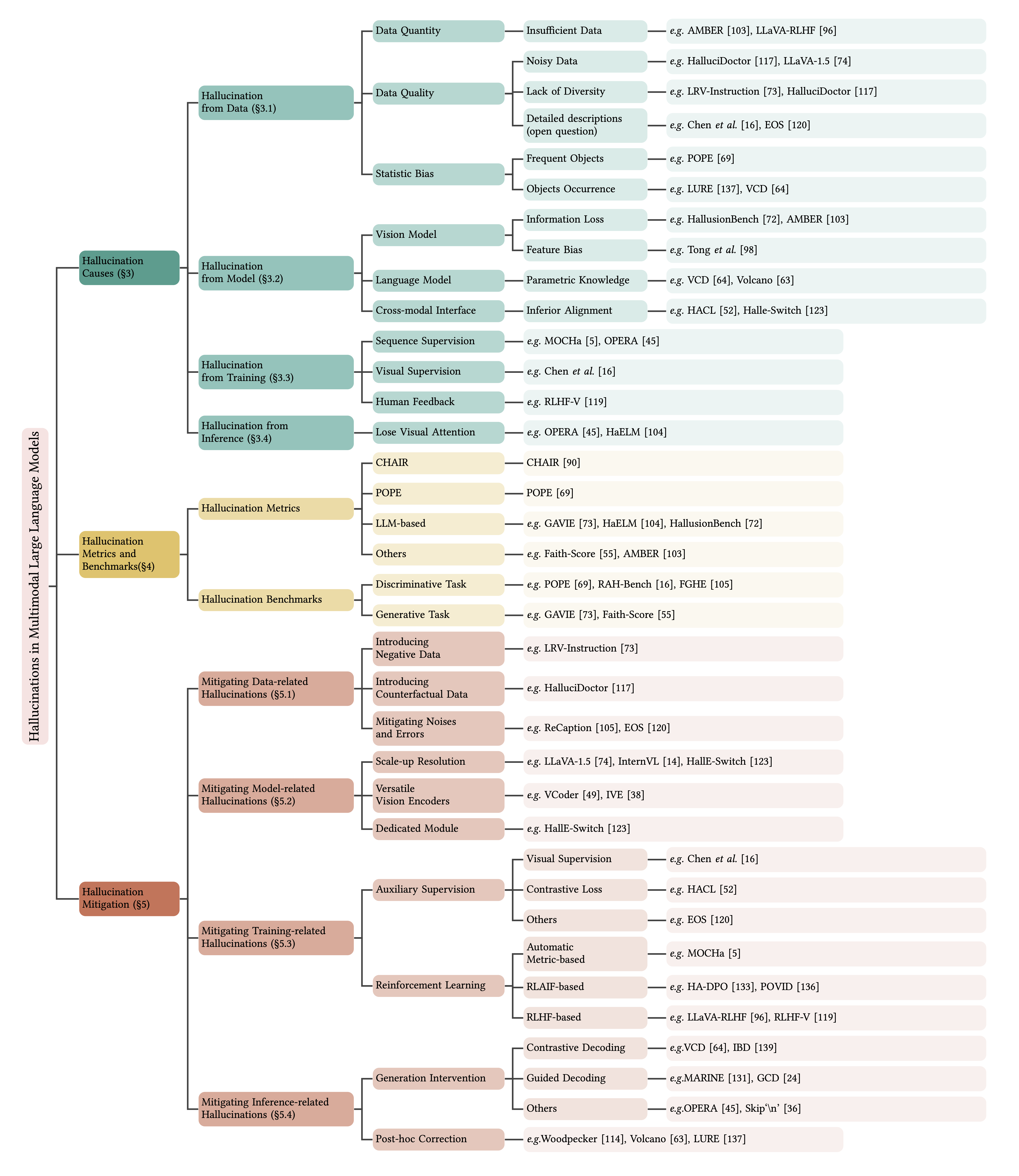
This survey provides a comprehensive analysis of the hallucination phenomenon in MLLMs. It reviews recent advances in identifying, evaluating, and mitigating hallucinations, offering an in-depth overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to tackle this issue.
The survey also analyzes the current challenges and limitations of MLLMs, formulating open questions that outline potential pathways for future research. By presenting a granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field.
Through a thorough and in-depth review, this survey contributes to the ongoing dialogue on enhancing the robustness and reliability of MLLMs. It provides valuable insights and resources for researchers and practitioners alike, making it a significant resource in the field of MLLMs.
